
Perplexity AI today launched the Deep Research Accuracy, Completeness, and Objectivity (DRACO) Benchmark, an open source tool designed to evaluate AI agents based on how users actually perform complex searches. The move aims to bridge the gap between AI models excelling at synthetic tasks and those capable of meeting authentic user needs.
DRACO is model agnostic, meaning it can be rerun as more powerful AI agents emerge, with Perplexity commit to publishing updated results. This also allows users to see performance gains directly reflected in products like Perplexity.ai’s Deep Research feature.
Assessing AI research prowess
Perplexity AI touts its deep search capabilities as state-of-the-art, citing strong performance on existing benchmarks such as Google DeepMind’s DeepSearchQA and Scale AI’s ResearchRubrics. This performance is attributed to a combination of cutting-edge AI models and Perplexity’s proprietary tools, including search infrastructure and code execution capabilities.
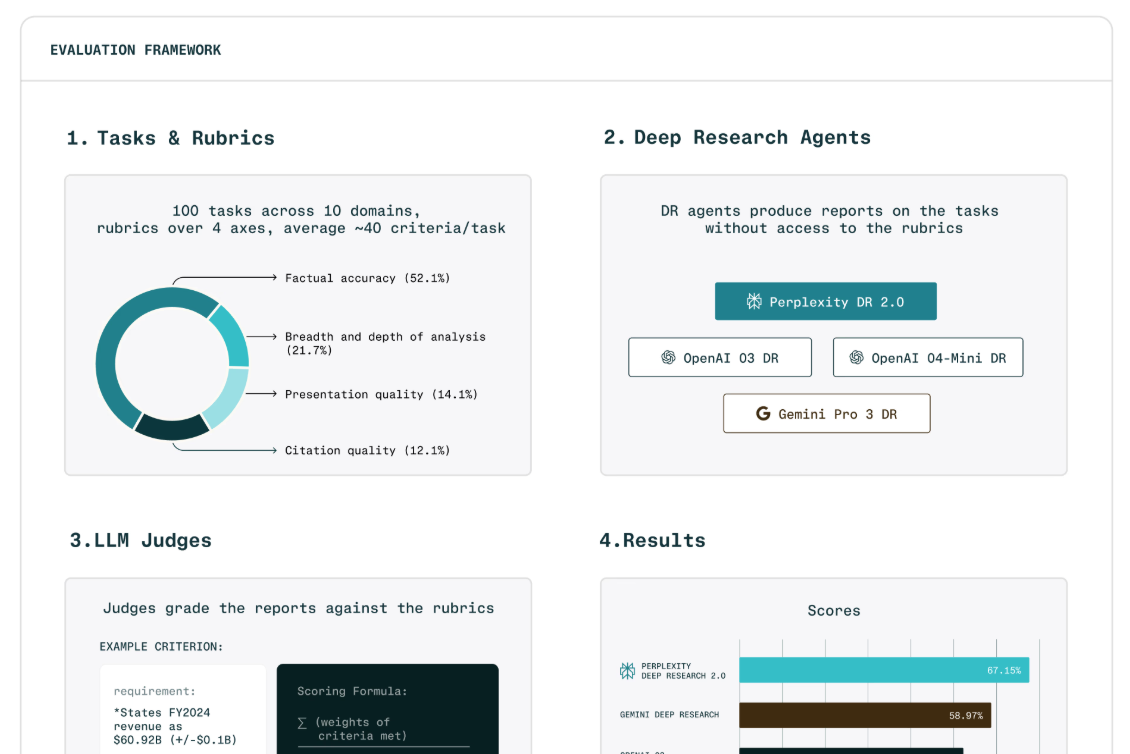
However, the company realized that existing benchmarks often fail to meet the nuanced requirements of real-world research. DRACO was developed from millions of production tasks across ten domains, including higher education, finance, law, medicine, and technology, to address this limitation.
Unlike benchmarks that test specific skills, DRACO focuses on synthesis across sources, nuanced analysis, and practical advice, while prioritizing accuracy and appropriate citations. The benchmark includes 100 curated tasks, each with detailed assessment rubrics developed by subject matter experts.
Production-oriented assessment
DRACO Benchmark tasks come from real user requests on Perplexity Deep Research. These requests undergo a rigorous five-step process: removal of personal information, increasing context and scope, filtering for objectivity and difficulties, and final review by experts. This process ensures that the benchmark reflects authentic user needs.
Rubric development was a meticulous process involving a data generation partner and subject matter experts, with approximately 45% of rubrics currently under review. These rubrics evaluate factual accuracy, breadth and depth of analysis, quality of presentation, and citation of sources, with weighted criteria and penalties for errors such as hallucinations.
Responses are evaluated using an LLM-as-judge protocol, where each criterion receives a binary verdict. This method, based on real research data, transforms subjective evaluation into verification of verifiable facts. Reliability was confirmed across multiple judge models, maintaining consistent relative rankings.
Tools and results
The DRACO benchmark is designed to evaluate agents equipped with a full set of search tools, including code execution and browser capabilities. This enables comprehensive evaluation of advanced AI search agents.
In evaluations of four deep research systems, Perplexity’s Deep Research demonstrated the highest success rates in all ten areas, notably excelling in law (89.4%) and academics (82.4%). This results in more reliable AI-generated responses for users in critical areas.
Performance gaps widened significantly in complex reasoning tasks, such as the custom assistant and “Needle in a Haystack” scenarios, where Perplexity outperformed the lowest-scoring system by more than 20 percentage points. These areas reflect common user needs for personalized recommendations and retrieving facts from large documents.
Perplexity’s extensive research also led to factual accuracy, breadth and depth of analysis, and quality of citations, highlighting its strength in dimensions crucial for reliable decision-making. Presentation quality was the only area in which another system showed comparable performance, indicating that the main research challenges lie in factual accuracy and analytical depth.
Notably, the best performing system also achieved the lowest latency, completing tasks significantly faster than its competitors. This efficiency, combined with accuracy, is attributed to Perplexity’s vertically integrated infrastructure, optimizing search and execution environments.
The road ahead
Perplexity plans to continually update the DRACO benchmarks as more robust AI models emerge. Improvements to Perplexity.ai’s deep search will also be reflected in benchmark scores.
Future iterations of the benchmark will expand language diversity, incorporate multi-round interactions, and expand domain coverage beyond the current single-round English-only scope.
The company is releasing the full benchmark, rubrics, and assessment prompt as open source, enabling other teams to build better search agents anchored in real-world tasks. The detailed methodology and results are available in a technical report and on Hugging Face.